问个问题,如何优化一条SQL语句?我们首先想到的肯定是建索引。对于ClickHouse也不例外,尤其是稀疏主键索引(类似传统数据库中的主键索引)对性能的影响非常大。在下文中,我将结合例子对稀疏主键索引进行详细解读。
注:本文内容主要参考官方文档,如果有余力,强烈建议先行阅读
数据准备
这里,我将就我比较熟悉的时序数据进行举例。首先通过如下SQL建表:
-- create dabase
create database test;
use test;
-- create table
CREATE TABLE cpu
(
`hostname` String,
`reginon` String,
`datacenter` String,
`timestamp` DateTime64(9,'Asia/Shanghai') CODEC (DoubleDelta),
`usage_user` Float64,
`usage_system` Float64
)
ENGINE = MergeTree() PRIMARY KEY tuple();
optimize table cpu final ;
并将本地的样本数据导入:
cat example/output.csv |clickhouse-client -d test -q 'INSERT into cpu FORMAT CSV'
output.csv是时序数据样本,时间间隔为1秒,包含了从2022-01-01 08:00:00到2022-01-15 07:59:59一共1209600条记录
optimize table 会强制进行merge之类的操作,使其达到最终状态
查询某段时间范围内的CPU使用率
SQL如下:
select ts, avg(usage_user) from cpu where timestamp > '2022-01-15 06:59:59.000000000' and timestamp < '2022-01-15 07:59:59.000000000' group by toStartOfMinute(timestamp) as ts order by ts;
统计结果如下:
60 rows in set. Elapsed: 0.025 sec. Processed 1.21 million rows, 9.72 MB (48.68 million rows/s., 391.19 MB/s.)
注意:clickhouse客户端对每次查询会给出简要的性能数据,便于用户进行简单分析
可以看到,尽管我们只查询了一个小时范围内的数据,但是依然扫描121万行数据,也就是进行了一次全表扫描!
显然,这样的是不够的,我们需要建立合理的稀疏索引,而它将显著提高查询性能。
稀疏主键索引
稀疏主键索引(Sparse Primary Indexes),以下简称稀疏索引。其功能上类似于MySQL中的主键索引,不过实现原理上是截然不同的。
长话短说,如若建立类似于B+树那种面向具体行的索引,在面对大数据场景时,必将占用大量内存和磁盘并且严重影响写入性能。此外,基于ClickHouse的实际使用场景考虑,也无需精确定位到每一行。
因此,其总体设计上,ClickHouse将数据块按组(粒度)划分,并通过下标(mark)标记。这种设计使得索引的内存占用足够小,同时仍能显著提高查询性能,尤其是OLAP场景下的大数据量的范围查询和数据分析。
配置Primary Key
稀疏索引可通过PRIMARY KEY语法指定,接下来让我们通过它来优化示例中的cpu表吧:
-- create table with timestamp as primary key
CREATE TABLE cpu_ts
(
`hostname` String,
`reginon` String,
`datacenter` String,
`timestamp` DateTime64(9,'Asia/Shanghai') CODEC (DoubleDelta),
`usage_user` Float64,
`usage_system` Float64
)
ENGINE = MergeTree()
PRIMARY KEY (timestamp)
ORDER BY (timestamp);
-- insert data from cpu
insert into cpu_ts select * from cpu;
optimize table cpu_ts final ;
执行相同的分析SQL:
select ts, avg(usage_user) from cpu_ts where timestamp > '2022-01-15 06:59:59.000000000' and timestamp < '2022-01-15 07:59:59.000000000' group by toStartOfMinute(timestamp) as ts order by ts;
输出如下:
60 rows in set. Elapsed: 0.004 sec. Processed 12.29 thousand rows, 196.58 KB (3.21 million rows/s., 51.31 MB/s.)
可以看到同样的结果,仅扫描5千多行! 下面,让我们通过EXPALIN来分析:
EXPLAIN indexes = 1 select ts, avg(usage_user) from cpu_ts where timestamp > '2022-01-15 06:59:59.000000000' and timestamp < '2022-01-15 07:59:59.000000000' group by toStartOfMinute(timestamp) as ts order by ts;
输出如下:
┌─explain────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┐
│ Expression (Projection) │
│ MergingSorted (Merge sorted streams for ORDER BY) │
│ MergeSorting (Merge sorted blocks for ORDER BY) │
│ PartialSorting (Sort each block for ORDER BY) │
│ Expression (Before ORDER BY) │
│ Aggregating │
│ Expression (Before GROUP BY) │
│ Filter (WHERE) │
│ SettingQuotaAndLimits (Set limits and quota after reading from storage) │
│ ReadFromMergeTree │
│ Indexes: │
│ PrimaryKey │
│ Keys: │
│ timestamp │
│ Condition: and((timestamp in (-inf, '1642204799.000000000')), (timestamp in ('1642201199.000000000', +inf))) │
│ Parts: 1/1 │
│ Granules: 1/148 │
└────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┘
17 rows in set. Elapsed: 0.003 sec.
可以看到,借助主键索引,我们仅仅扫描了一个粒度的数据,优化效果十分明显 !
实现原理
数据排布
我们不妨从实际磁盘上的数据文件来对ClickHouse有个总体上的理解。首先,让我们来看下cpu_ts表的某个partall_1_1_0/在磁盘上的存储结构:
all_1_1_0其结构表示为: {分区}_{最小block数}_{最大block数}_{表示经历了几次merge}
-rw-r----- 1 clickhouse clickhouse 589 Jun 26 05:42 checksums.txt
-rw-r----- 1 clickhouse clickhouse 179 Jun 26 05:42 columns.txt
-rw-r----- 1 clickhouse clickhouse 7 Jun 26 05:42 count.txt
-rw-r----- 1 clickhouse clickhouse 55K Jun 26 05:42 datacenter.bin
-rw-r----- 1 clickhouse clickhouse 3.4K Jun 26 05:42 datacenter.mrk2
-rw-r----- 1 clickhouse clickhouse 10 Jun 26 05:42 default_compression_codec.txt
-rw-r----- 1 clickhouse clickhouse 34K Jun 26 05:42 hostname.bin
-rw-r----- 1 clickhouse clickhouse 3.4K Jun 26 05:42 hostname.mrk2
-rw-r----- 1 clickhouse clickhouse 1.2K Jun 26 05:42 primary.idx
-rw-r----- 1 clickhouse clickhouse 51K Jun 26 05:42 reginon.bin
-rw-r----- 1 clickhouse clickhouse 3.4K Jun 26 05:42 reginon.mrk2
-rw-r----- 1 clickhouse clickhouse 147K Jun 26 05:42 timestamp.bin
-rw-r----- 1 clickhouse clickhouse 3.4K Jun 26 05:42 timestamp.mrk2
-rw-r----- 1 clickhouse clickhouse 2.5M Jun 26 05:42 usage_system.bin
-rw-r----- 1 clickhouse clickhouse 3.4K Jun 26 05:42 usage_system.mrk2
-rw-r----- 1 clickhouse clickhouse 2.5M Jun 26 05:42 usage_user.bin
-rw-r----- 1 clickhouse clickhouse 3.4K Jun 26 05:42 usage_user.mrk2
其中主要文件如下:
- *.bin:每个表中的列上的值压缩后的数据文件
- column.txt:此表中所有列以及每列的类型
- default_compression_codec.txt:数据文件默认的压缩算法
- primary.idx:数据索引,后文详解
- *.mrk2:数据标记,后文详解
- count.txt:此part中数据的行数
注意:通过指定的PRIMARY KEY,其数据行会以timestamp升序排列并生成主键索引,对于timestamp相同的行按照ORDER BY中的hostname进行(若PRIMARY KEY和ORDER BY分别指定,则PRIMARY KEY必须是ORDER BY的前缀)。
索引建立
上文提到ClickHouse会对数据进行分组,其中某一列内的值自然也是按照组(粒度,默认8192行)进行划分的。粒度,可以简单理解为ClickHouse中一组不可划分的最小数据单元。
当处理数据时,ClickHouse会读取整个粒度内的所有数据,而不是一行一行地读取(批处理的思想无处不在哈)。因此对于cpu_ts表内的数据,会被划分为148个组(ceil(1210000/8192=148),其整体数据排布如下所示:
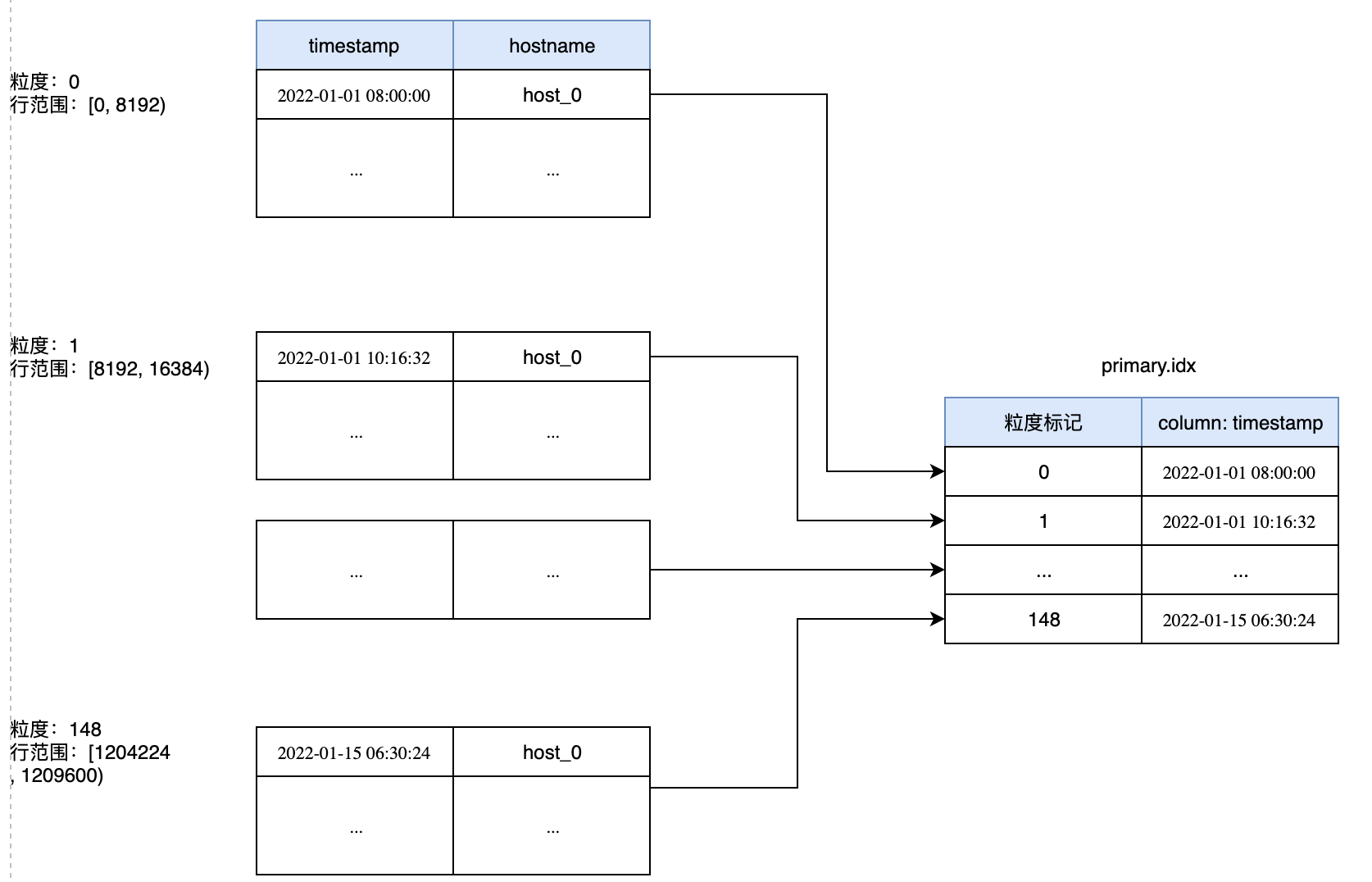
从上图可以看出,表内数据被按照每8192行划分为148个粒度,每个组内取PRIMARY KEY中指定列的最小数据作为数据,并通过标记给其编号,存储在primary.idx中(可以将其理解为一个数组,标记就是下标)。我们使用od命令od -l -j 0 -N 32 primary.idx将primary.idx打印出来:
0000000 1640995200000000000 1641003392000000000
0000020 1641011584000000000 1641019776000000000
# 粒度数组:[1640995200000000000, 1641003392000000000, 1641011584000000000, 1641019776000000000]
(1642151554000000000-1642143362000000000)/1000000000 = 8192
当我们根据timestamp字段进行过滤时,ClickHouse会通过二分搜索算法对primary.txt中的timestamp列进行搜索,找到对应的组标记,从而实现快速定位。例如对于示例查询语句,ClickHouse定位到的标记是148,那么又要如何通过标记反向找到实际的数据块呢?
数据定位
这里,ClickHouse是通过引入{column_name}.mrk文件来解决的,mrk文件存储了粒度编号与压缩前后数据的偏移量(offset),其大致结构如下图所示:
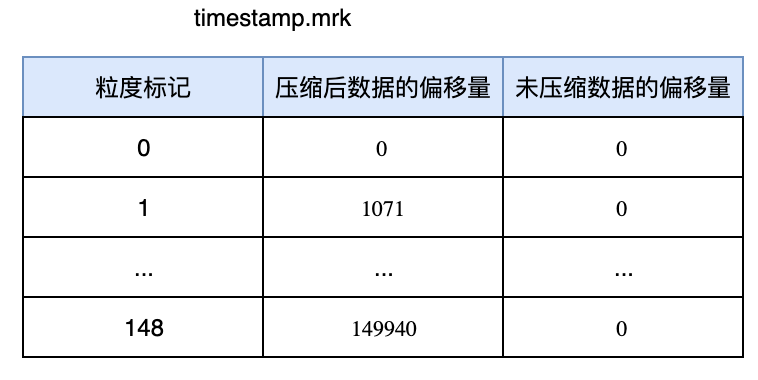
使用od命令od -l -j 0 -N 24 timestamp.mrk2输出如下:
0000000 0 0
0000020 8192 1071
0000040 0 8192
# (0, 0, 8192)为一组,表示压缩后偏移量为0,压缩前偏移量为0,粒度内一共8192行
# (1071, 0, 8192)为一组,表示压缩后偏移量为1071, 压缩前偏移量为0,粒度内一共8192行
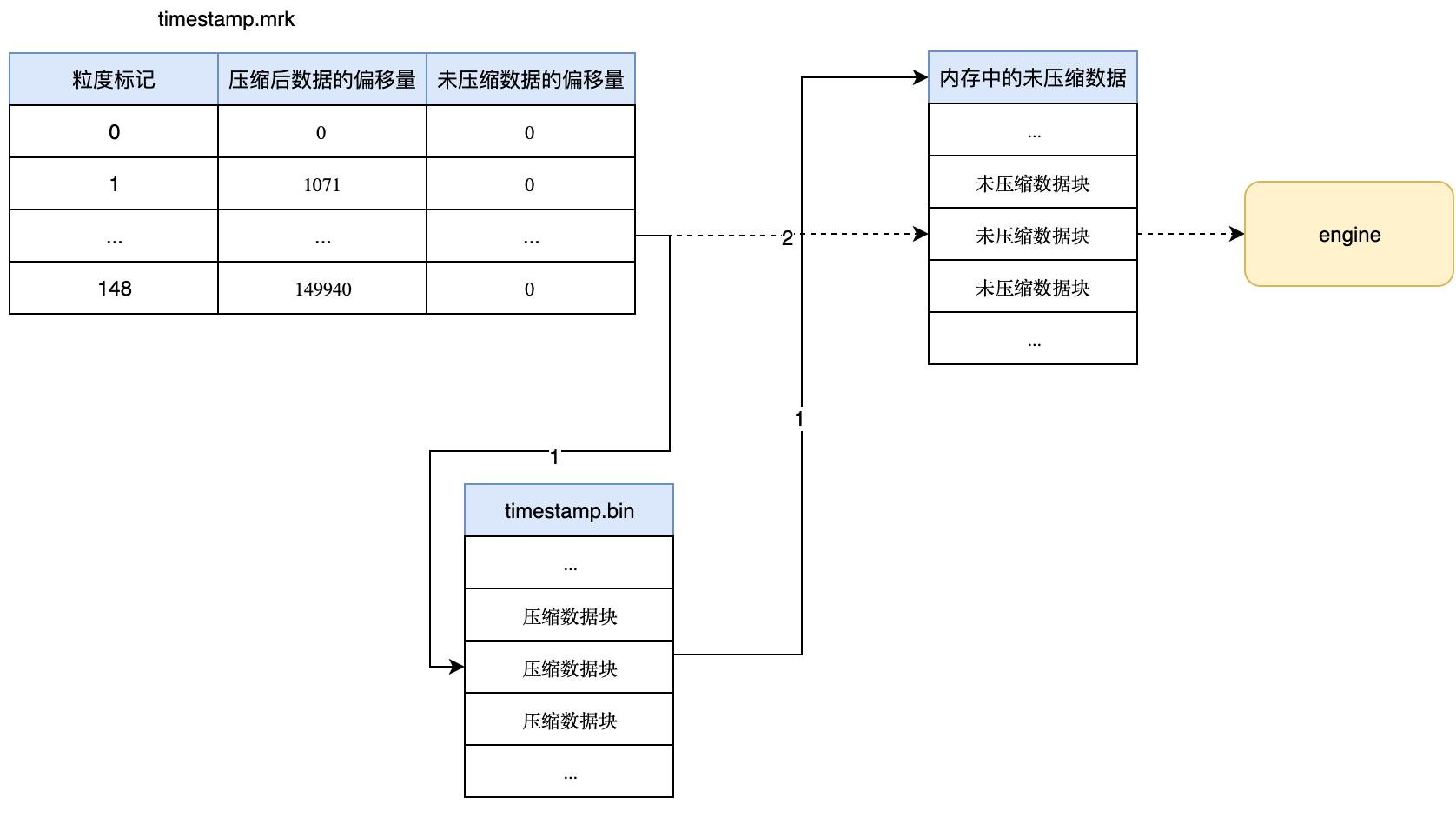
在前文中,我们已经通过primary.idx已经拿到了具体的粒度编号(mark),接着我们通过编号在{column}.mrk中找到对应的数据压缩前后的偏移量。然后通过以下2个步骤将数据发送给分析引擎:
- 通过压缩后的偏移量定位到数据文件(*.bin)中的数据块并解压后加载到内存中
- 根据压缩前的偏移量定位到内存中相关未压缩的数据块,然后将其发送到分析引擎
总结
综上所述,ClickHouse的稀疏索引是综合权衡之下的产物,尽管其使用了一种看起来比较粗粒度的索引机制,但依然能获得达到相当客观的性能提升。毕竟默认8192行的粒度,对于动辄上亿级别的OLAP场景来说已经算是比较细粒度的了,同时得益于ClickHouse强大的并行计算与分析能力,其查询的性能需求是能够满足的。
不过实际的使用场景中,由于PRIMARY KEY一旦定义就没法更改了,而实际的查询方式又往往是变化无常的。因此单靠稀疏索引有时无法满足实际需求。
ClickHouse为此额外提供了两种方案:一种是通过定义新的PRIMARY KEY,并通过创建新表或物化表之类来重建;而另外一种则是类似传统二级索引的机制叫做跳数索引来处理,这些我将在后序文章中进行介绍:)