在ClickHouse稀疏索引原理解读文章中,我们通过设置合理的稀疏主键索引,极大地优化了通用场景下的查询性能。然而,我们也发现,当我们想通过别的列(标签)进行过滤时,由于未能命中稀疏索引,就变成了全表扫描。
例如,对于cpu_ts表,当我们要通过别的维度,例如hostname,进行查询分析时,ClickHouse会对hostname列的所有值进行全表扫描,再根据WHERE中的条件对值进行过滤。
在传统的关系型数据库中,我们可以通过创建一个或多个的二级索引(B+树实现)来加快查询效率。而ClickHouse中也同样提供了一种类似的方式,不过由于ClickHouse是纯列式存储,磁盘上并没有单独的行数据,因此没法利用二级索引来构建面向行的索引。
因此ClickHouse通过一种被称为跳数索引的索引机制来达到传统二级索引的效果,之所以叫跳数,是因为数据的定位是通过跳过那些肯定不满足过滤条件的数据块来实现的。
通过hostname进行查询
添加跳数索引前
在cpu_ts表中,hostname字段每1024行就会重新生产一份随机字符串用来模拟实际场景。这里我们使用如下SQL查询主机fa9c19a5-39eb-4bea-97df-5a6b82e5e947的CPU使用率:
select ts, avg(usage_user) from cpu_ts where hostname = 'fa9c19a5-39eb-4bea-97df-5a6b82e5e947' group by toStartOfMinute(timestamp) as ts order by ts;
结果如下:
Query id: e34e54e8-8c9f-4f5b-ba29-83f54a095167
┌──────────────────ts─┬───avg(usage_user)─┐
│ 2022-01-15 07:24:00 │ 77.7843137254902 │
│ 2022-01-15 07:25:00 │ 75.23333333333333 │
│ 2022-01-15 07:26:00 │ 73.96666666666667 │
│ 2022-01-15 07:27:00 │ 79.7 │
│ 2022-01-15 07:28:00 │ 77.68333333333334 │
│ 2022-01-15 07:29:00 │ 73.03333333333333 │
│ 2022-01-15 07:30:00 │ 72.21666666666667 │
│ 2022-01-15 07:31:00 │ 75.11666666666666 │
│ 2022-01-15 07:32:00 │ 80.28333333333333 │
│ 2022-01-15 07:33:00 │ 82.33333333333333 │
│ 2022-01-15 07:34:00 │ 80 │
│ 2022-01-15 07:35:00 │ 84.33333333333333 │
│ 2022-01-15 07:36:00 │ 85.98333333333333 │
│ 2022-01-15 07:37:00 │ 76.01666666666667 │
│ 2022-01-15 07:38:00 │ 67.51666666666667 │
│ 2022-01-15 07:39:00 │ 71.2 │
│ 2022-01-15 07:40:00 │ 78.11666666666666 │
│ 2022-01-15 07:41:00 │ 78.71428571428571 │
└─────────────────────┴───────────────────┘
18 rows in set. Elapsed: 0.015 sec. Processed 1.21 million rows, 54.52 MB (82.17 million rows/s., 3.70 GB/s.)
可以看到,这里ClickHouse扫描12100万行,显然进行了一次全表扫描。我们执行EXPLAIN语句:
explain indexes=1 select ts, avg(usage_user) from cpu_ts where hostname = 'fa9c19a5-39eb-4bea-97df-5a6b82e5e947' group by toStartOfMinute(timestamp) as ts order by ts;
结果如下:
Query id: 7cd58c55-3fc6-4394-9579-55edde163192
┌─explain───────────────────────────────────────────────────────────────────────────────┐
│ Expression (Projection) │
│ MergingSorted (Merge sorted streams for ORDER BY) │
│ MergeSorting (Merge sorted blocks for ORDER BY) │
│ PartialSorting (Sort each block for ORDER BY) │
│ Expression (Before ORDER BY) │
│ Aggregating │
│ Expression (Before GROUP BY) │
│ SettingQuotaAndLimits (Set limits and quota after reading from storage) │
��� ReadFromMergeTree │
│ Indexes: │
│ PrimaryKey │
│ Condition: true │
│ Parts: 1/1 │
│ Granules: 148/148 │
└───────────────────────────────────────────────────────────────────────────────────────┘
可以看到,由于WHERE条件未指定timestamp,因此无法利用稀疏索引来减少扫描量。
添加跳数索引后
接着,让我们通过如下ALTER语句给hostname列添加跳数索引:
ALTER TABLE test.cpu_ts ADD INDEX idx_hostname hostname TYPE set(100) GRANULARITY 2;
然后,我们再用同样的语句进行查询主机fa9c19a5-39eb-4bea-97df-5a6b82e5e947的CPU使用率,得到结果如下:
Query id: a9b7fc8d-bb76-4969-984c-d9561f5ff56b
┌──────────────────ts─┬───avg(usage_user)─┐
│ 2022-01-15 07:24:00 │ 77.7843137254902 │
│ 2022-01-15 07:25:00 │ 75.23333333333333 │
│ 2022-01-15 07:26:00 │ 73.96666666666667 │
│ 2022-01-15 07:27:00 │ 79.7 │
│ 2022-01-15 07:28:00 │ 77.68333333333334 │
│ 2022-01-15 07:29:00 │ 73.03333333333333 │
│ 2022-01-15 07:30:00 │ 72.21666666666667 │
│ 2022-01-15 07:31:00 │ 75.11666666666666 │
│ 2022-01-15 07:32:00 │ 80.28333333333333 │
│ 2022-01-15 07:33:00 │ 82.33333333333333 │
│ 2022-01-15 07:34:00 │ 80 │
│ 2022-01-15 07:35:00 │ 84.33333333333333 │
│ 2022-01-15 07:36:00 │ 85.98333333333333 │
│ 2022-01-15 07:37:00 │ 76.01666666666667 │
│ 2022-01-15 07:38:00 │ 67.51666666666667 │
│ 2022-01-15 07:39:00 │ 71.2 │
│ 2022-01-15 07:40:00 │ 78.11666666666666 │
│ 2022-01-15 07:41:00 │ 78.71428571428571 │
└─────────────────────┴───────────────────┘
18 rows in set. Elapsed: 0.023 sec. Processed 13.57 thousand rows, 678.56 KB (583.11 thousand rows/s., 29.16 MB/s.)
可以看到,同样的过滤条件,此时仅仅扫描了13570行。我们用EXPLAIN语句分析:
explain indexes=1 select ts, avg(usage_user) from cpu_ts where hostname = 'fa9c19a5-39eb-4bea-97df-5a6b82e5e947' group by toStartOfMinute(timestamp) as ts order by ts;
输出如下:
Query id: b0c15f16-9a04-4b87-a46d-f94f1df8273d
┌─explain───────────────────────────────────────────────────────────────────────────────┐
│ Expression (Projection) │
│ MergingSorted (Merge sorted streams for ORDER BY) │
│ MergeSorting (Merge sorted blocks for ORDER BY) │
│ PartialSorting (Sort each block for ORDER BY) │
│ Expression (Before ORDER BY) │
│ Aggregating │
│ Expression (Before GROUP BY) │
│ SettingQuotaAndLimits (Set limits and quota after reading from storage) │
��� ReadFromMergeTree │
│ Indexes: │
│ PrimaryKey │
│ Condition: true │
│ Parts: 1/1 │
│ Granules: 148/148 │
│ Skip │
│ Name: idx_hostname │
│ Description: set GRANULARITY 2 │
│ Parts: 1/1 │
│ Granules: 1/148 │
└───────────────────────────────────────────────────────────────────────────────────────┘
我们可以看到,尽管未命中稀疏索引,但是得益于跳数索引,ClickHouse仅仅只扫描1357行,整整减少了9000多倍的扫描量!
实现原理
当我们条件跳数索引之后,在分区目录下会分别生成skp_idx_[IndexName].idx与skp_idx_[IndexName].mrk2文件
-rw-r----- 1 clickhouse clickhouse 41386 Jul 25 15:44 skp_idx_idx_hostname.idx
-rw-r----- 1 clickhouse clickhouse 1776 Jul 25 15:44 skp_idx_idx_hostname.mrk2
与稀疏索引一样,以.idx后缀的文件为索引文件,而以.mrk2后缀的文件则为标记文件。
索引建立
跳数索引 建立过程中,ClickHouse会以GRANULARITY的值,每GRANULARITY个index_granularity(默认8192行)来生成一行跳数索引,这里对于索引idx_hostname,ClickHouse会以每两个索引粒度聚合生成一条映射关系,并存于skp_idx_idx_hostname.idx中:
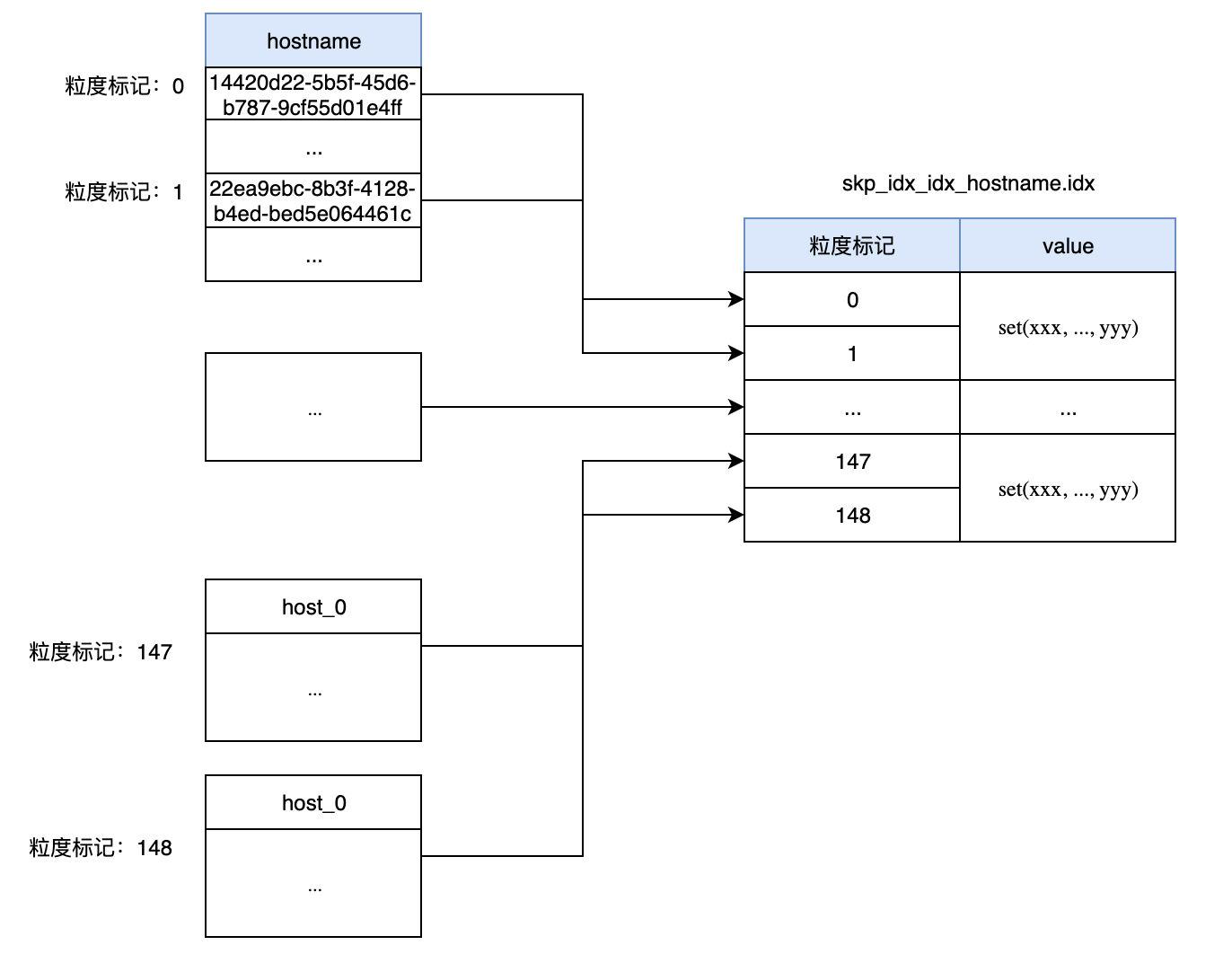
如图中所示,idx文件中保存了标记与value(根据索引类型执行不同的生成算法)的映射关系,当WHERE条件中包含跳数索引所关联的过滤条件时,就会根据value判断来进行剪枝。
这里与稀疏索引不同的是,跳数索引只能遍历idx文件中的所有记录(复杂度为O(n))来剪枝,而稀疏索引则能通过二分查找(复杂度为O(logn))来定位数据块
数据定位
与稀疏索引定位类似,ClickHouse会根据WHERE中的条件,对数据块进行剪枝(即跳过那些肯定不包含目标数据的数据),从而得到所有标记的集合,最后再通过加载标记集合所关联的数据块进行后续分析:
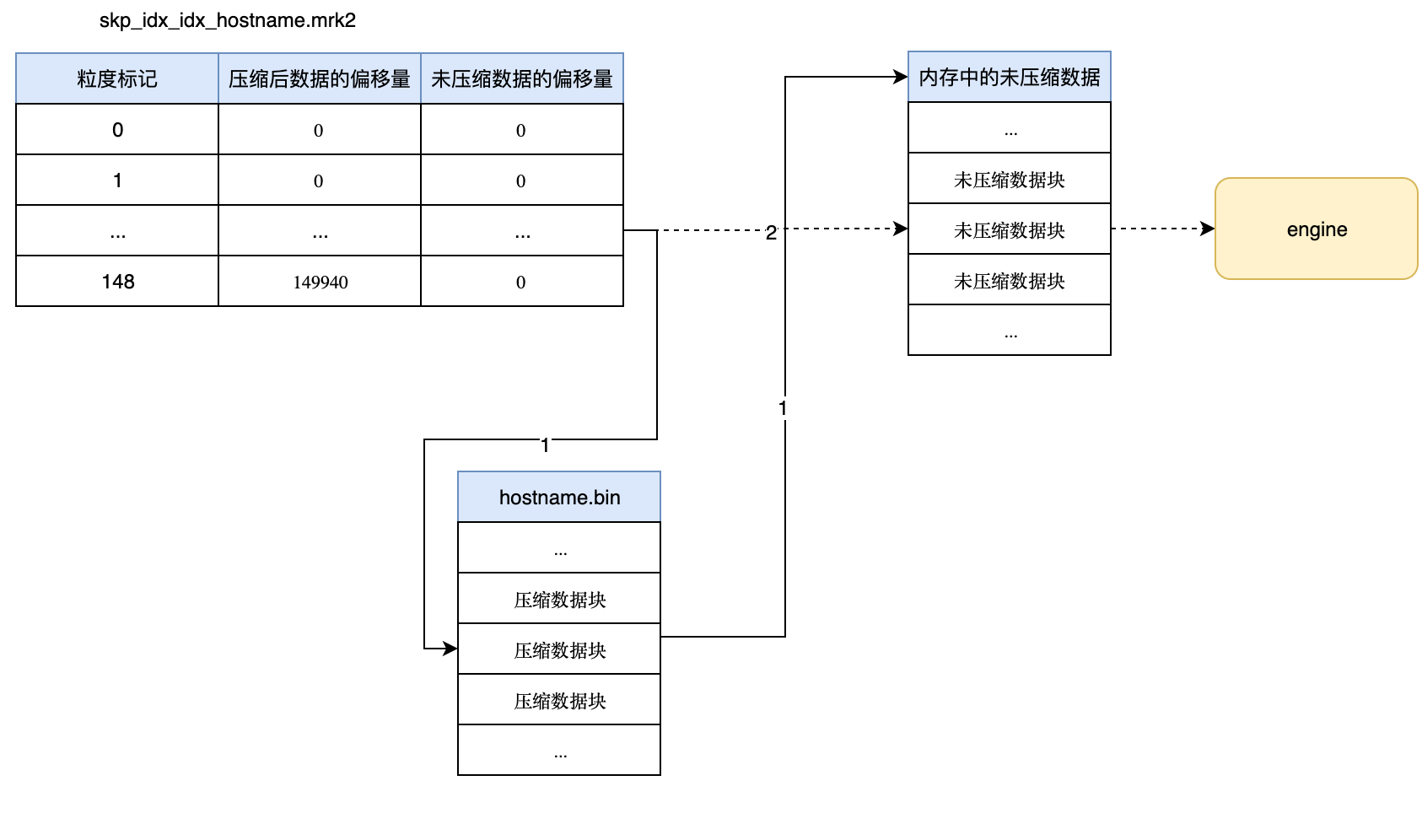
一些注意事项
尽管从直觉上来看,跳数索引用法与传统关系型数据库的二级索引十分类似,但是其并不能像二级索引(b+数)那样直接定位出数据所在的行,只能通过跳过的方式来减少扫描量。
在cpu_ts表中,若某个主机名(localhost)均匀地分布在整个时间范围内(极端情况下,每两个index_granularity就出现一次),那么当我们通过WHERE hostname='localhost'进行过滤时,则无法跳过任何数据块(即全表扫描)!
我们重新生成一份样本数据并写入表cpu_ts_hostname,其中每1024行中会包好一行特殊记录起hostname为localhost,接着让我们执行如下语句:
select ts, avg(usage_user) from cpu_ts_hostname where hostname = 'localhost' group by toStartOfMinute(timestamp) as ts order by ts;
得到结果:
...
│ 2022-01-15 05:24:00 │ 74 │
│ 2022-01-15 05:41:00 │ 83 │
│ 2022-01-15 05:58:00 │ 67 │
│ 2022-01-15 06:15:00 │ 67 │
│ 2022-01-15 06:32:00 │ 20 │
│ 2022-01-15 06:50:00 │ 45 │
│ 2022-01-15 07:07:00 │ 59 │
│ 2022-01-15 07:24:00 │ 81 │
│ 2022-01-15 07:41:00 │ 79 │
│ 2022-01-15 07:58:00 │ 29 │
└─────────────────────┴─────────────────┘
1181 rows in set. Elapsed: 0.023 sec. Processed 1.21 million rows, 73.75 MB (53.68 million rows/s., 3.27 GB/s.)
通过EXPLAIN分析:
Query id: cb51d2c0-28df-4ccf-98d2-2db4c1d9fb34
┌─explain───────────────────────────────────────────────────────────────────────────────┐
│ Expression (Projection) │
│ MergingSorted (Merge sorted streams for ORDER BY) │
│ MergeSorting (Merge sorted blocks for ORDER BY) │
│ PartialSorting (Sort each block for ORDER BY) │
│ Expression (Before ORDER BY) │
│ Aggregating │
│ Expression (Before GROUP BY) │
│ SettingQuotaAndLimits (Set limits and quota after reading from storage) │
��� ReadFromMergeTree │
│ Indexes: │
│ PrimaryKey │
│ Condition: true │
│ Parts: 2/2 │
│ Granules: 148/148 │
│ Skip │
│ Name: idx_hostname │
│ Description: set GRANULARITY 2 │
│ Parts: 2/2 │
│ Granules: 0/148 │
└───────────────────────────────────────────────────────────────────────────────────────┘
可以看到,此时跳数索引未跳过任何一个数据块,对于这种情况,我们完全无法利用跳数索引来降低扫描量,而建立跳数索引造成的成本浪费则无法避免
这种情况在可观测性数据领域里还是比较普遍,标签的值大多不会随时间变化而变化,同样的数据也会随时间反复出现。常见的如集群名,主机名,租户ID等
因此我们需要对是否建立跳数索引保持谨慎,必须先仔细分析数据与PRIMARY KEY的关联度,并反复测试验证,否则建立跳数索引非但不能提升查询性能,反而会造成额外开销且影响写入性能。
总结
本篇文章是ClickHouse稀疏索引原理解读的延伸,当稀疏索引无法满足业务,我们可以通过建立跳数索引来显著提高查询性能(当然还可以通过重建稀疏索引,物化表等方式)。
同时,我们还介绍了跳数索引的简单用法、底层实现原理(原理上与稀疏索引类似),以及使用跳数索引时需要注意的事项,我们不应盲目地试图通过创建跳数来提升查询性能,而必须先仔细分析数据分布并反复测试!