在众多的ClickHouse表引擎中,当属MergeTree(合并树)最为常用也最为完备,适用于中绝大部分场景,因此搞懂MergeTree对与理解ClickHouse至关重要!
在本文中,我将通过主要从数据模型、数据写入、数据读取3个方面来阐述MergeTree的实现
本文需要读者具备一定的ClickHouse使用经验,譬如建表、写入、查询等
数据模型
在MergeTree引擎底层实现中,从上至下主要有以下3种数据模型组成:Part、Block、PrimaryKey
Part
这里需要注意的时,Part不是Partition,对于一张表来说:
- Part是用来存储一组行对应于,在磁盘上对应于一个数据目录,目录里有列数据、索引等信息
- Partition则是一种虚拟的概念,在磁盘上没有具体的表示,不过可以说某个Partition包含多个Part
在建表的DDL中,我们可通过PARTITION BY参数来配置分区规则,ClickHouse会根据分区规则生成不同分区ID,从而在写入时将数据落盘到对应分区中。一但有数据写入,ClickHouse则根据分区ID创建对应的Part目录。
其中目录的命名规则为{PartiionID}_{MinBlockNum}_{MaxBlockNum}_{Level}:
- PartiionID:即为分区ID
- MinBlockNum:表示最小数据块编号,后续解释
- MaxBlockNum:表示最大数据块编号,后续解释
- Level:表示该Part被合并过的次数,对于每个新建Part目录而言,其初始值为0,每合并一次则累积加1
目录中的文件主要包括如下部分:
- 数据相关:{Column}.mrk、{Column}.mrk2、{Column}.bin、primary.idx(mrk, mrk2应该是版本不同)
- 二级索引相关:skp_idx_{Column}.idx、skp_idx_{Column}.mrk
此外,每个Part在逻辑上被划分为多个粒度(粒度大小由index_granularity或index_granularity_bytes控制);而在物理上,列数据则被划分为多个数据块。
Block
Block即为数据块,在内存中由三元组(列数据,列类型,列名)组成。是ClickHouse中的最小数据处理单元,例如,在查询过程中,数据是一个块接着一个块被处理的。
而在磁盘上,其则通过排序、压缩序列化后生成压缩数据块并存储于{Column}.bin中,其中表示如下所示:
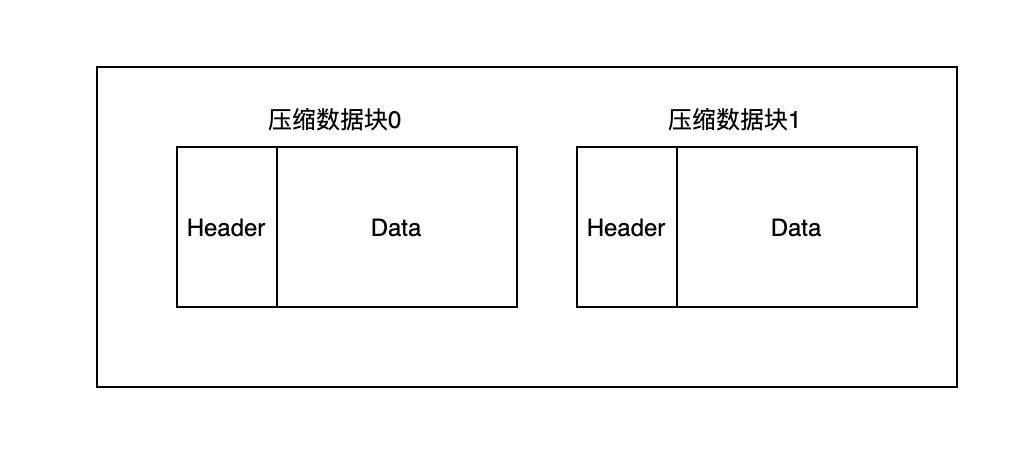
其中,头信息(Header)部分包含3种信息:
- CompressionMethod:Uint8,压缩方法,如LZ4, ZSTD
- CompressedSize:UInt32,压缩后的字节大小
- UncompressedSize:UInt32,压缩前的字节大小
其中每个数据块的大小都会被控制在64K-1MB的范围内(由min_compress_block_size和max_compress_block_size指定)。
这里我们为什么要将{Column}.bin划分成多个数据块呢?其目的主要包括:
- 数据压缩后虽然可以显著减少数据大小,但是解压缩会带来性能损耗,因此需要控制被压缩数据的大小,以求性能与压缩率之间的平衡(这条我也不太理解,还请评论区大佬指教:))
- 当读取数据时,需要将数据加载到内存中再解压,通过压缩数据块,我们可以不用加载整个
.bin文件,从而进一步降低读取范围
PrimaryKey
主键索引(Primary Key)是一张表不可或缺的一部分,你可以不指定,但是这会导致每次查询都是全表扫描从而几乎不可用。
PrimaryKey主要是由{Column}.mrk,primary.idx和{Column}.bin三者协同实现,其中:
- primary.idx:保存主键与标记的映射关系
- {Column}.mrk:保存标记与数据块偏移量的映射关系
- {Column}.bin:保存数据块
具体实现可以参考我之前的文章
数据写入
ClickHouse的数据写入流程是比较简单直接的,整体流程如下图所示:
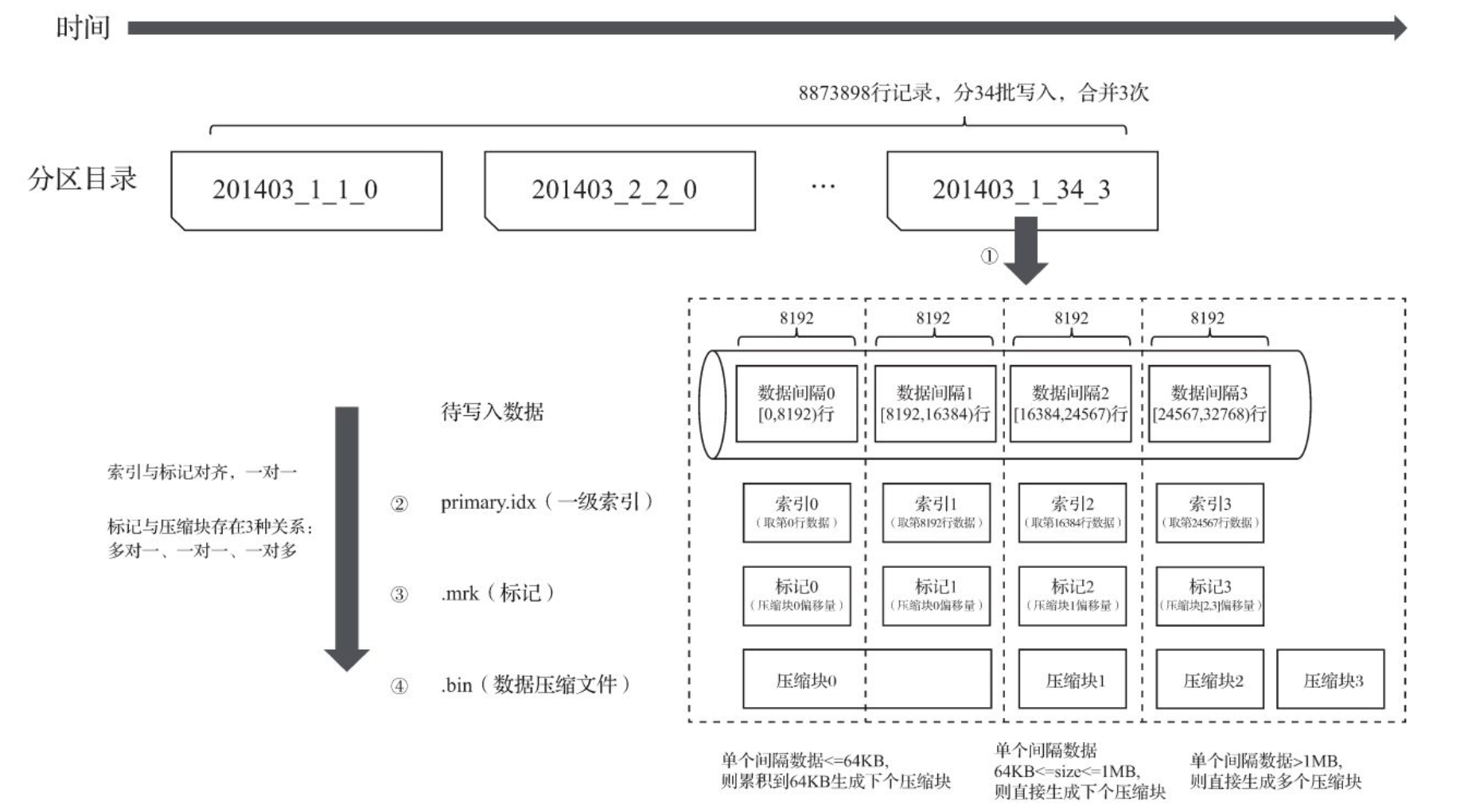
每收到写入请求,ClickHouse就会生成一个新的Part目录,接着按index_granularity定义的粒度将数据划分,并依次进行处理,生成primary.idx文件,针对每一行生成.mrk和.bin文件。
合并
写入结束后,ClickHouse的后台线程会周期性地选择一些Part进行合并,合并后数据依然有序。
在上文中,我们提到的MinBlockNum此时会取各个part中的MinBlockNum最小值,而MaxBlockNum则会取各个part中的MinBlockNum最小值。例如201403_1_1_0和201403_2_2_0合并后,生成的新part目录为201403_1_2_1。
查询
查询的过程本质上可以看做是不断缩小数据扫描的过程,流程如下图所示:
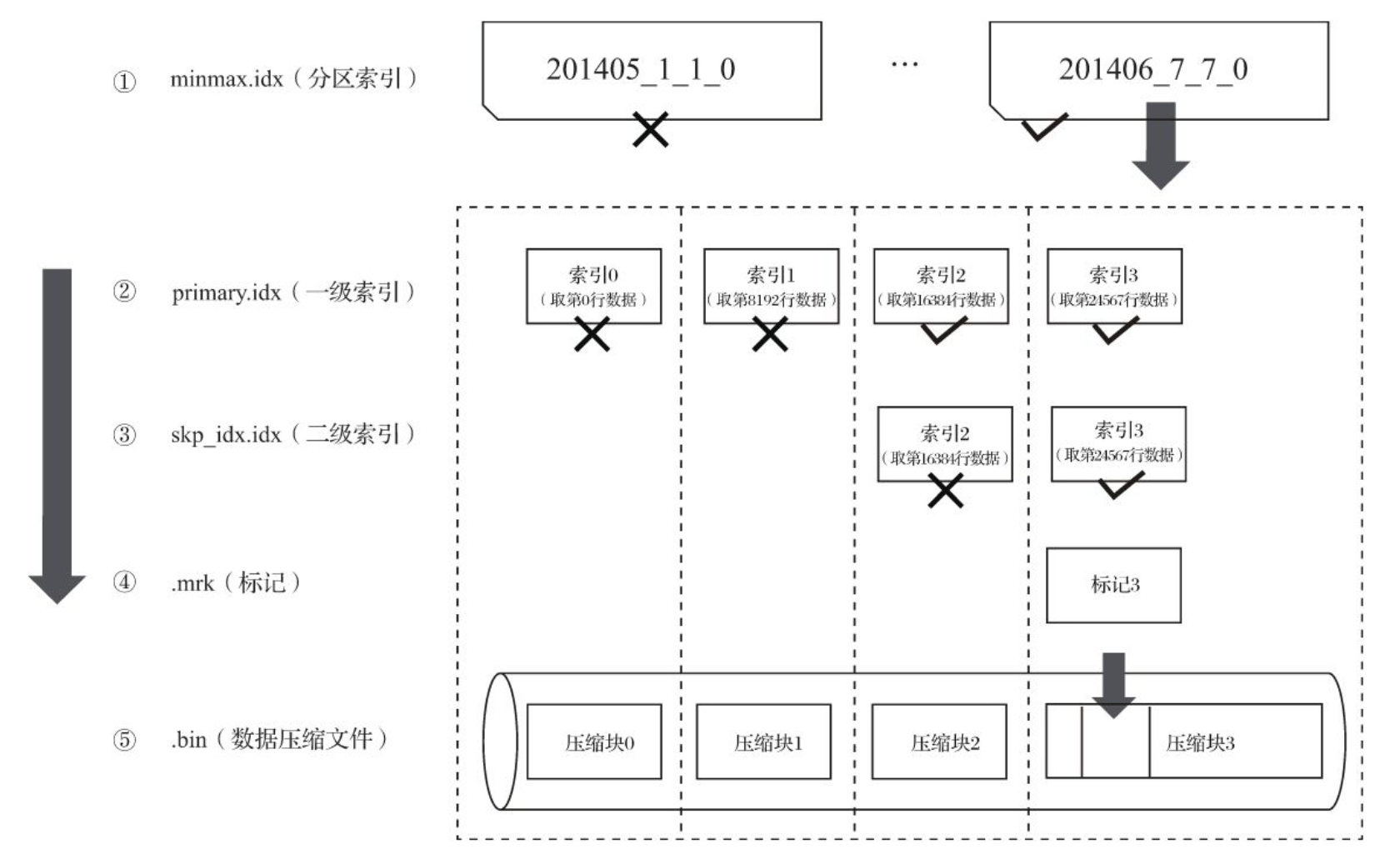
当ClickHouse收到查询请求时,其会首先尝试定位到具体的分区,然后扫描所有的part,然后通过part目录中的一级、二级索引定位到标记,再通过标记找到压缩数据块,并将其加载到内存中进行处理。
此外,为了提升查询性能,ClickHouse还是用了vectorized query execution和以及少量runtime code generation技术,从CPU层面提升性能(这块内容比较多,这里就不详解了,后续我将尝试再写一篇博客来介绍)。
总结
本文,我们首先从数据模型层面自顶向下分别介绍了分区、Part、Block、PrimaryKey,它们构建起了MergeTree的总体框架。然后,我们分别介绍了数据写入与数据查询流程,将数据模型串联起来,并详细介绍了它们之间是如何相互协同的。
总体看来,MergeTree实现上还是比较简单易懂的,希望本文能对你有所帮助