当我们需要在实际生产环境中使用ClickHouse时,高可用与可扩展是绕不开的话题,因此ClickHouse也提供了分布式的相关机制来应对这些问题。在下文中,我们将主要从副本机制、分片机制两个个方面来对齐进行介绍。
副本机制
ClickHouse通过扩展MergeTree为ReplicatedMergeTree来创建副本表引擎(通过在MergeTree添加Replicated前缀来表示副本表引擎)。这里需要注意的是,副本表并非一种具体的表引擎,而是一种逻辑上的表引擎,实际数据的存取仍然通过MergeTree来完成。
注意:这里,我们假定集群名为local,且包含两个节点chi-0和chi-1
建表
ReplicatedMergeTree通过类似如下语句进行创建:
CREATE TABLE table_name
(
EventDate DateTime,
CounterID UInt32,
UserID UInt32,
ver UInt16
) ENGINE = ReplicatedReplacingMergeTree('/clickhouse/tables/{cluster}-{shard}/table_name', '{replica}', ver)
PARTITION BY toYYYYMM(EventDate)
ORDER BY (CounterID, EventDate, intHash32(UserID))
SAMPLE BY intHash32(UserID);
有两个参数需要重点说明一下,分别为zoo_path和replica_name参数:
- zoo_path: 表示表所在的zk路径
- replica_name: 表示副本名称,通常为主机名
ClickHouse会在zk中建立路径zoo_path,并在zoo_path的子目录/replicas下根据replica_name创建副本标识,因此可以看到replica_name参数的作用主要就是用来作为副本ID。
我们这里假定首先在chi-0节点上执行了建表语句
- 其首先创建一个副本实例,进行一些初始化的工作,在zk上创建相关节点
- 接着在/replicas节点下注册副本实例chi-0
- 启用监听任务,监听/log节点
- 参与leader节点选举(通过向/leader_election写入数据,谁先写入成功谁就是leader)
接着,我们在chi-1节点上执行建表语句:
- 首先也是创建副本实例,进行初始化工作
- 接着在/replicas节点下注册副本实例chi-1
- 启用监听任务,监听/log节点
- 参与leader节点选举(此时由于chi-0节点上已经执行过建表流程了,因此chi-0为leader副本)
/log节点非常重要,用来记录各种操作LogEntry包括获取part,合并part,删除分区等等操作
写入
接着,我们通过执行INSERT INTO语句向chi-0节点写入数据(当写入请求被发到从节点时,从节点会将其转发到主节点)。
此时,会首先在本地完成分区数据的写入,然后向/blocks节点写入该分区的block_id
block是ClickHouse中的最小数据单元,这里在/blocks节点中写入block_id主要是为了后续数据的去重
接着向/log节点推送日志,日志信息如下所示:
format version: 4
create_time: 2022-09-04 14:30:58
source replica: chi-0
block_id: 20220904_5211346952104599192_1472622755444261990
get
20220904_269677_269677_0
part_type: Compact
...
日志内容中主要包含了源节点chi-0,操作类型get,分区目录20220904_269677_269677_0,以及block_id。
接下来就轮到副本节点chi-1的回合了,由于chi-1也监听了/log节点,通过分析日志信息,它需要执行获取part的操作。因此它获取到日志信息后,会将其推送到/replicas/chi-1/queue/节点下,稍后在执行。
把日志推送到队列中,而不是立马执行。主要是处于性能的考虑,比如同一时间段可能会收到很多日志信息,可以需要将其攒批处理以提升性能
随后,chi-1节点从队列中获取任务开始执行,其首先从/replicas获取所有副本,选择一个合适的副本(chi-0),对其发起数据下载的请求
选择一个合适的副本,往往需要考虑副本拥有数据的新旧程度以及副本节点的负载
chi-0收到下载请求后,发送相关part的数据给chi-1,chi-1完成写入
合并
合并操作本质上也是由各个副本独立完成的,不会涉及到任何part数据的传输。首先,合并操作可以在任何节点上触发,但是都必须由主节点来发布合并任务。
- 假设,在从节点chi-1上,我们触发了合并请求(可通过OPTIMIZE操作触发)
- 此时,chi-1不会立马执行合并操作,而是向主节点chi-0发送请求,并由chi-0来指定合并计划
- chi-0将合并计划生成操作日志推送到/log下
- 所有副本(包括主副本)监听到操作日志后,将合并任务推送到各自的/queue下
- 副本各自监听/queue,收到合并任务后,各自分别执行合并任务
查询
当客户端发起查询请求时,由于设计多个副本,因此需要考虑负载均衡的问题。对此,ClickHouse会根据配置负载均衡算法来选择一个合适的副本,由load_babalancing参数决定。
分片机制
为解决可扩展性的问题,ClickHouse引入了分片机制,主要通过Distributed引擎来定义,DDL如下所示:
CREATE TABLE [IF NOT EXISTS] [db.]table_name [ON CLUSTER cluster]
(
name1 [type1] [DEFAULT|MATERIALIZED|ALIAS expr1],
name2 [type2] [DEFAULT|MATERIALIZED|ALIAS expr2],
...
) ENGINE = Distributed(cluster, database, table[, sharding_key[, policy_name]])
[SETTINGS name=value, ...]
参数说明如下所示:
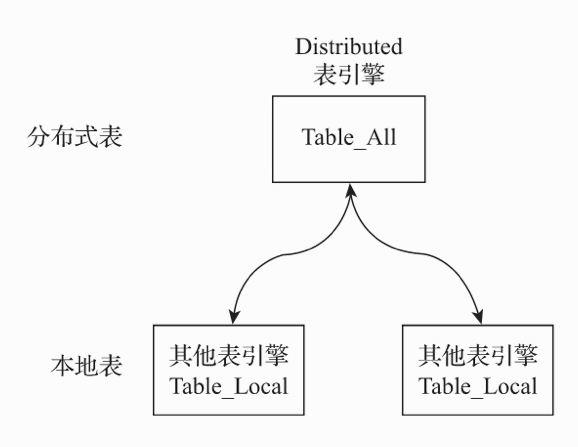
cluster:表示集群名database:表示所管辖的本地表的数据库名table:表示所管辖的本地表的表明sharding_key:表示分片键,
通过Distributed定义的分布式表,同样也是虚拟表,实际数据由其管理的本地表存储,如图所示:
分片规则
分片规则主要是用以路由数据,决定数据存储在哪个分片中,规则主要由sharding_key和weight参数决定:
sharding_key:用来生成分片的key
weight:表示分片权重,通过服务端的配置来设置。其可以用来调整分片之间数据的分布,默认都是1。若某个分片的weight越大,则数据会向该分片倾斜。
假定只有0号和1号两个分片,其中weight分别为10和20,sharding_key为rand()(生成随机整数),则最终的表达式为如下所示:
shard_number = rand() % 30
当shard_number位于[0, 10)之间时,数据被路由到0号分片
当shard_number位于[10, 30)之间时,数据则被路由到1号分片
写入
通过上述的分片规则,我们就可以确定写入请求要被写入到那个节点上了,此时再对该节点发起请求。这种方式是非常高效也是官方的推荐方式,因为其直接在客户端决定了数据流向,无需额外的路由操作,不过缺点就是客户端实现比较复杂。
除此之外,我们还可以直接往Distributed表里插入数据,此时数据的分片和路由则由ClickHouse节点代理了,当数据不属于当前节点上的分片时,则需要将数据发送到目标分片所在的节点上,从而会导致额外的网络传输,影响性能。
查询
与写入不同的是,分布式查询是直接查询Distributed表。
- 节点收到查询请求后,节点将分布式查询转换为本地表查询,并将查询下发到各个分片上
- 各个分片各自执行本地表查询,然后将查询结果返回节点
- 最后,节点将结果集合并成最终结果,返回给客户端
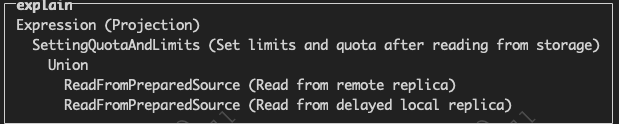
我们通过EXPLAIN语句可以看到,分布式查询会分别从两个分片中获取数据并合并
小心子查询
当涉及到子查询时,需要特别小心,因为很容易导致结果错误或者性能下降。
这里,我们假定一个4节点的集群,users_all和orders_all分别为本地表users和orders的分布式表,单副本双分片
结果错误
select username from users_all where id IN (select distinct(user_id) from orders)
- ch-0首先将该SQL转换成本地SQL:
select username from users where id IN (select distinct(user_id) from orders),然后下发本地SQL到users的分片节点上执行 - 分片节点得到子结果后,将结果返回给ch-0,ch-0合并并生成最终结果。
看起来没问题?其实并非如此,此时得到的结果是不正确的。
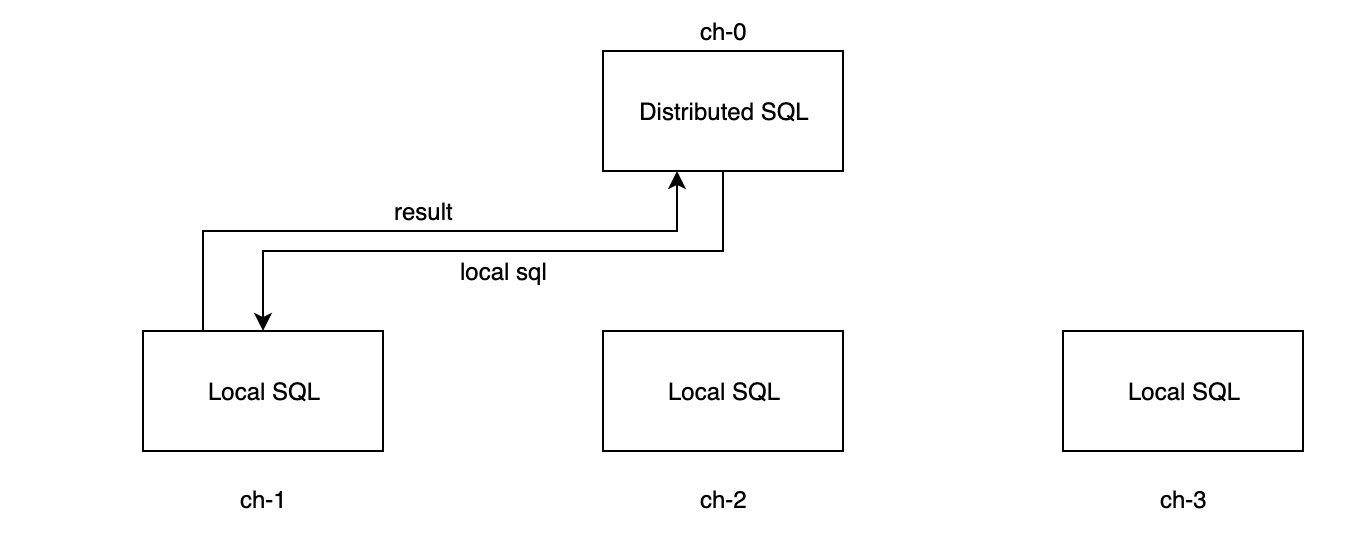
- 假若orders表的分片在ch-2和ch-3节点上,而orders表的分片在ch-0和ch-1上,则子查询的结果均为空,因此最终结果也为空
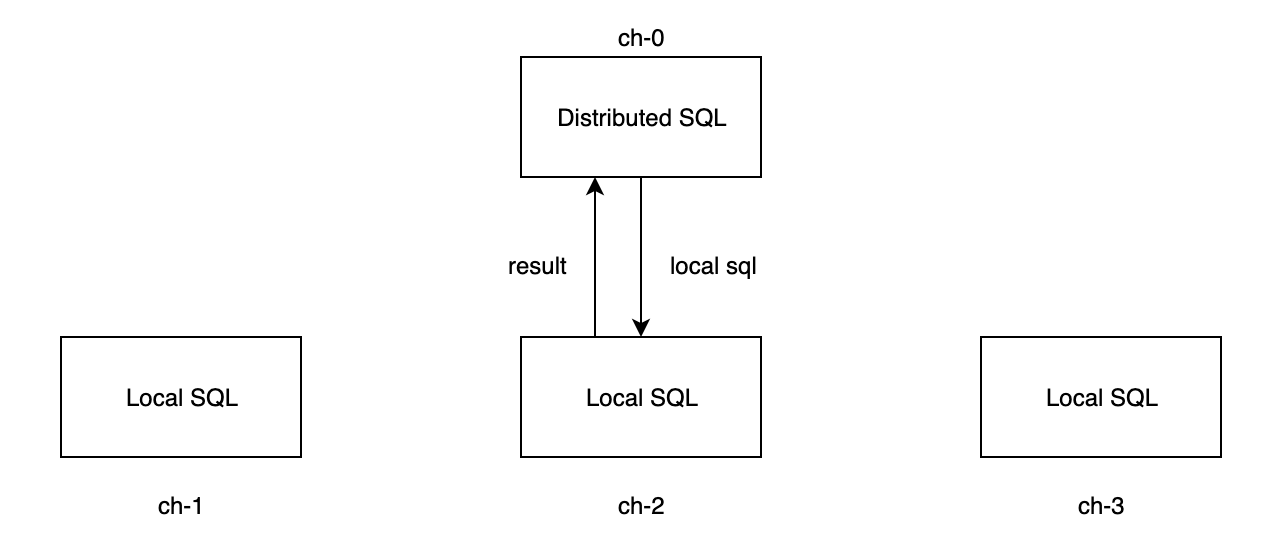
- 假若orders表的分片在ch-2和ch-3节点上,而orders表的分片在ch-0和ch-2上,则两个子查询中的只有ch-2节点上的子查询能得到结果,因此最终结果仅为正确结果的一部分
这是因为子查询为本地表查询,若节点上不包含orders的分片数据,那么就只会得到空数据,因此子查询语句同样需要改为分布式查询
性能下降
此时,SQL则会变成
select username from users_all where id IN (select distinct(user_id) from orders_all)
ch-0首先将该SQL转换成本地SQL:
select username from users where id IN (select distinct(user_id) from orders_all),然后下发到users所在的分片节点上执行分片节点再将其子查询转换为本地SQL:
select distinct(user_id) from orders下发到orders所在的分片节点上执行,得到结果集orders所在的分片节点分别执行分布式查询得到结果集,再执行原SQL得到子结果集,返回给ch-0,ch-0合并并生成最终结果。
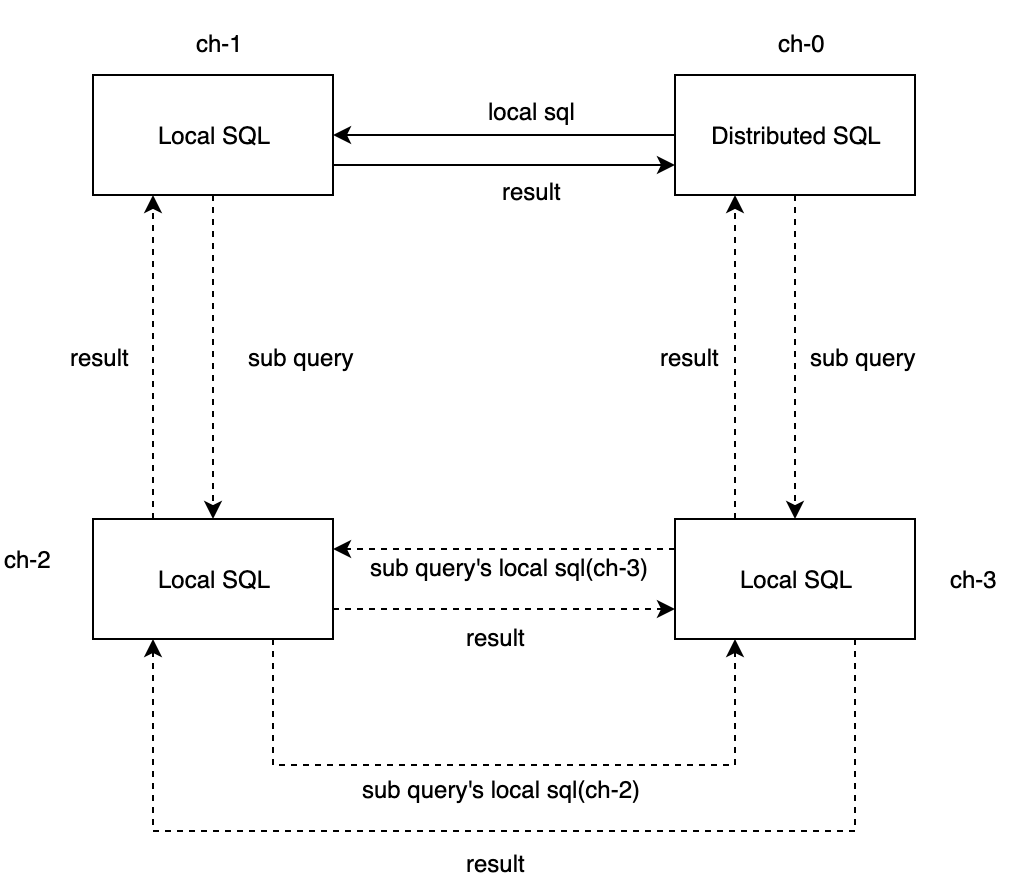
可以明显看到,子查询在分片ch-2和ch-3上分别执行了分布式查询(ch-2下发子查询的本地SQL到ch-3,而ch-3下发子查询的本地SQL到ch-2),同样的结果集被查询了两次,从而导致查询性能下降,且orders的分片数越多,性能下降越明显。
幸运的是,ClickHouse提供了GOBAL IN语句来解决此类子查询问题,此时ClickHouse会先单独执行子查询,得到的结果存在一个临时内存表里,并将内存表的数据发送到users的分片节点上。
总结
在本文中,我们分别介绍了ClickHouse是如何利用副本机制用以解决高可用问题场景,以及利用分片机制用以解决可扩展性问题。
总的来说,ClickHouse的采用了多主架构,避免了主从架构的单点问题,将负载均摊到各个节点,并且给予用户足够的灵活度,例如可以将本地表转换为分布式表、将分布式表转换成本地表、调整权重控制数据倾斜度等等。
然而,其缺点也比较明显,一则配置比较繁琐,需要较多的人工运维操作;二则,严重依赖zookeeper,基本所有操作都需要zookeeper来进行信息的同步与交换,当存在很多表时会对zookeeper产生较大压力,从而影响整体集群的性能。